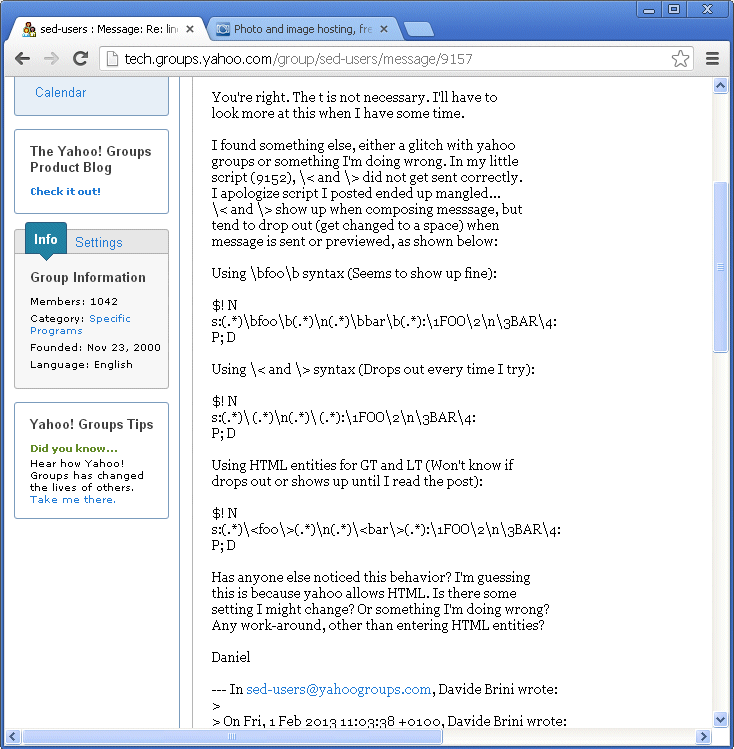
Daniel
2013-01-28 20:18:23 UTC
This came up in a recent cross-Atlantic conversation. :)
The problem: How to apply a change when a *combination*
of lines occurs, eg when the word "foo" appears in line
N and the word "bar" appears in line N+1. How then to
apply the change in line N (or line N+1)? For example,
change word "foo" to "FOO" and word "bar" to "BAR".
Here's a test file I dreamed up:
food foot foo
bare bark bar
bar bark bare
bark bar bare
foot foo food
bark bar bare
foot foo food
foo foot food
bar bark bare
foot foo food
Here's the desired output:
food foot FOO
bare bark BAR
bar bark bare
bark bar bare
foot FOO food
bark BAR bare
foot foo food
FOO foot food
BAR bark bare
foot foo food
I tried doing this in bash and couldn't make it
work. I do have a possible sed solution.
Thought I'd post this, see if anyone would like
to take a look, either sed or bash (or whatever!).
Daniel
The problem: How to apply a change when a *combination*
of lines occurs, eg when the word "foo" appears in line
N and the word "bar" appears in line N+1. How then to
apply the change in line N (or line N+1)? For example,
change word "foo" to "FOO" and word "bar" to "BAR".
Here's a test file I dreamed up:
food foot foo
bare bark bar
bar bark bare
bark bar bare
foot foo food
bark bar bare
foot foo food
foo foot food
bar bark bare
foot foo food
Here's the desired output:
food foot FOO
bare bark BAR
bar bark bare
bark bar bare
foot FOO food
bark BAR bare
foot foo food
FOO foot food
BAR bark bare
foot foo food
I tried doing this in bash and couldn't make it
work. I do have a possible sed solution.
Thought I'd post this, see if anyone would like
to take a look, either sed or bash (or whatever!).
Daniel